web信息打点-完成了-但是没完成
这个专题只是简单的信息搜集,具体的漏洞利用到后面再讲
js系列
在Javascript中也存在变量和函数,当存在可控变量及函数调用即可参数漏洞JS开发的WEB应用和PHP,JAVA,NET等区别在于即没有源代码
也可以通过浏览器的查看源代码获取真实的点。获取URL,获取Js敏感信息,获取代码传参等
所以相当于JS开发的WEB应用属于白盒测试(默认有源码参考),一般会在Js中寻找更多的URL地址
在JS代码逻辑(加密算法,APIkey配置,验证逻辑等)进行后期安全测试。
前提:web应用可以采用前端和后端语言开发
后端语言:php java python .NET 等等浏览器看不到真实代码
前端语言:html js 和开发框架可以在浏览器中看到源代码
如何快速获取价值信息?
src= //链接地址
path= //路径
method:"get" //请求方法
http.get("
method:"post"
http.post("
$.ajax
http://service.httpposthttp://service.httpget小工具:
显示全部状态码 URLFinder.exe -u http://www.baidu.com -s all -m 3 显示200和403状态码 URLFinder.exe -u http://www.baidu.com -s 200,403 -m 3 结果分开保存 导出全部 URLFinder.exe -s all -m 3 -f url.txt -o . 只导出html URLFinder.exe -s all -m 3 -f url.txt -o res.html 结果统一保存 URLFinder.exe -s all -m 3 -ff url.txt -o . -a 自定义user-agent请求头 -b 自定义baseurl路径 -c 请求添加cookie -d 指定获取的域名,支持正则表达式 -f 批量url抓取,需指定url文本路径 -ff 与-f区别:全部抓取的数据,视为同一个url的结果来处理(只打印一份结果 | 只会输出一份结果) -h 帮助信息 -i 加载yaml配置文件,可自定义请求头、抓取规则等(不存在时,会在当前目录创建一个默认yaml配置文件) -m 抓取模式: 1 正常抓取(默认) 2 深入抓取 (URL深入一层 JS深入三层 防止抓偏) 3 安全深入抓取(过滤delete,remove等敏感路由) -max 最大抓取数 -o 结果导出到csv、json、html文件,需指定导出文件目录(.代表当前目录) -s 显示指定状态码,all为显示全部 -t 设置线程数(默认50) -time 设置超时时间(默认5,单位秒) -u 目标URL -x 设置代理,格式: http://username:password@127.0.0.1:8877 -z 提取所有目录对404链接进行fuzz(只对主域名下的链接生效,需要与 -s 一起使用) 1 目录递减fuzz 2 2级目录组合fuzz 3 3级目录组合fuzz(适合少量链接使用)
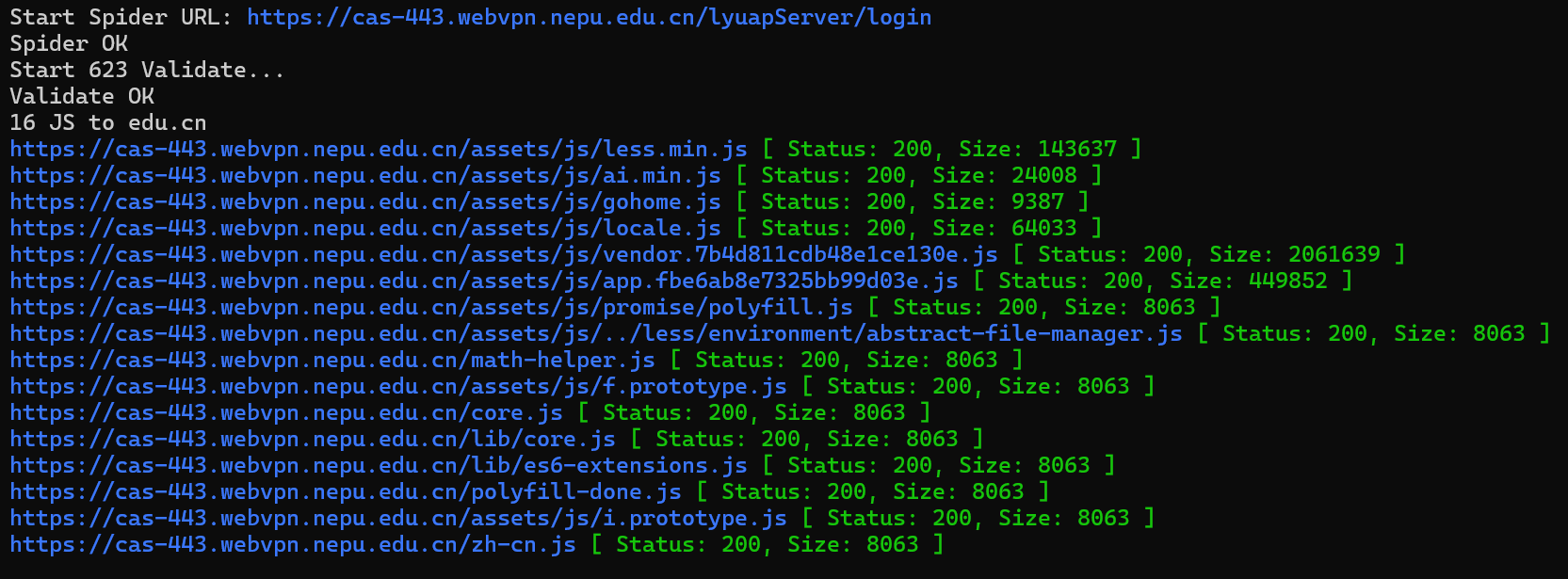
可以看到扫描的对应的js目录
FFUF
ffuf.exe -w js-2024.txt -u https://life.huamengdy.com/FUZZ -t 200
Fuzz Faster U Fool - v2.0.0
HTTP OPTIONS:
-H Header `"Name: Value"`, separated by colon. Multiple -H flags are accepted.
-X HTTP method to use
-b Cookie data `"NAME1=VALUE1; NAME2=VALUE2"` for copy as curl functionality.
-d POST data
-http2 Use HTTP2 protocol (default: false)
-ignore-body Do not fetch the response content. (default: false)
-r Follow redirects (default: false)
-recursion Scan recursively. Only FUZZ keyword is supported, and URL (-u) has to end in it. (default: false)
-recursion-depth Maximum recursion depth. (default: 0)
-recursion-strategy Recursion strategy: "default" for a redirect based, and "greedy" to recurse on all matches (default: default)
-replay-proxy Replay matched requests using this proxy.
-sni Target TLS SNI, does not support FUZZ keyword
-timeout HTTP request timeout in seconds. (default: 10)
-u Target URL
-x Proxy URL (SOCKS5 or HTTP). For example: http://127.0.0.1:8080 or socks5://127.0.0.1:8080
GENERAL OPTIONS:
-V Show version information. (default: false)
-ac Automatically calibrate filtering options (default: false)
-acc Custom auto-calibration string. Can be used multiple times. Implies -ac
-ach Per host autocalibration (default: false)
-ack Autocalibration keyword (default: FUZZ)
-acs Autocalibration strategy: "basic" or "advanced" (default: basic)
-c Colorize output. (default: false)
-config Load configuration from a file
-json JSON output, printing newline-delimited JSON records (default: false)
-maxtime Maximum running time in seconds for entire process. (default: 0)
-maxtime-job Maximum running time in seconds per job. (default: 0)
-noninteractive Disable the interactive console functionality (default: false)
-p Seconds of `delay` between requests, or a range of random delay. For example "0.1" or "0.1-2.0"
-rate Rate of requests per second (default: 0)
-s Do not print additional information (silent mode) (default: false)
-sa Stop on all error cases. Implies -sf and -se. (default: false)
-scraperfile Custom scraper file path
-scrapers Active scraper groups (default: all)
-se Stop on spurious errors (default: false)
-search Search for a FFUFHASH payload from ffuf history
-sf Stop when > 95% of responses return 403 Forbidden (default: false)
-t Number of concurrent threads. (default: 40)
-v Verbose output, printing full URL and redirect location (if any) with the results. (default: false)
MATCHER OPTIONS:
-mc Match HTTP status codes, or "all" for everything. (default: 200,204,301,302,307,401,403,405,500)
-ml Match amount of lines in response
-mmode Matcher set operator. Either of: and, or (default: or)
-mr Match regexp
-ms Match HTTP response size
-mt Match how many milliseconds to the first response byte, either greater or less than. EG: >100 or <100
-mw Match amount of words in response
FILTER OPTIONS:
-fc Filter HTTP status codes from response. Comma separated list of codes and ranges
-fl Filter by amount of lines in response. Comma separated list of line counts and ranges
-fmode Filter set operator. Either of: and, or (default: or)
-fr Filter regexp
-fs Filter HTTP response size. Comma separated list of sizes and ranges
-ft Filter by number of milliseconds to the first response byte, either greater or less than. EG: >100 or <100
-fw Filter by amount of words in response. Comma separated list of word counts and ranges
INPUT OPTIONS:
-D DirSearch wordlist compatibility mode. Used in conjunction with -e flag. (default: false)
-e Comma separated list of extensions. Extends FUZZ keyword.
-ic Ignore wordlist comments (default: false)
-input-cmd Command producing the input. --input-num is required when using this input method. Overrides -w.
-input-num Number of inputs to test. Used in conjunction with --input-cmd. (default: 100)
-input-shell Shell to be used for running command
-mode Multi-wordlist operation mode. Available modes: clusterbomb, pitchfork, sniper (default: clusterbomb)
-request File containing the raw http request
-request-proto Protocol to use along with raw request (default: https)
-w Wordlist file path and (optional) keyword separated by colon. eg. '/path/to/wordlist:KEYWORD'
OUTPUT OPTIONS:
-debug-log Write all of the internal logging to the specified file.
-o Write output to file
-od Directory path to store matched results to.
-of Output file format. Available formats: json, ejson, html, md, csv, ecsv (or, 'all' for all formats) (default: json)
-or Don't create the output file if we don't have results (default: false)
EXAMPLE USAGE:
Fuzz file paths from wordlist.txt, match all responses but filter out those with content-size 42.
Colored, verbose output.
ffuf -w wordlist.txt -u https://example.org/FUZZ -mc all -fs 42 -c -v
Fuzz Host-header, match HTTP 200 responses.
ffuf -w hosts.txt -u https://example.org/ -H "Host: FUZZ" -mc 200
Fuzz POST JSON data. Match all responses not containing text "error".
ffuf -w entries.txt -u https://example.org/ -X POST -H "Content-Type: application/json" \
-d '{"name": "FUZZ", "anotherkey": "anothervalue"}' -fr "error"
Fuzz multiple locations. Match only responses reflecting the value of "VAL" keyword. Colored.
ffuf -w params.txt:PARAM -w values.txt:VAL -u https://example.org/?PARAM=VAL -mr "VAL" -c
More information and examples: https://github.com/ffuf/ffuf
这个就是对js目录进行爆破,看是否有对应的js文件然后显示出来
叽里咕噜太多了,工具我补药敲了
PackerFuzzer.py
python PackerFuzzer.py -h python PackerFuzzer.py -u 目标地址
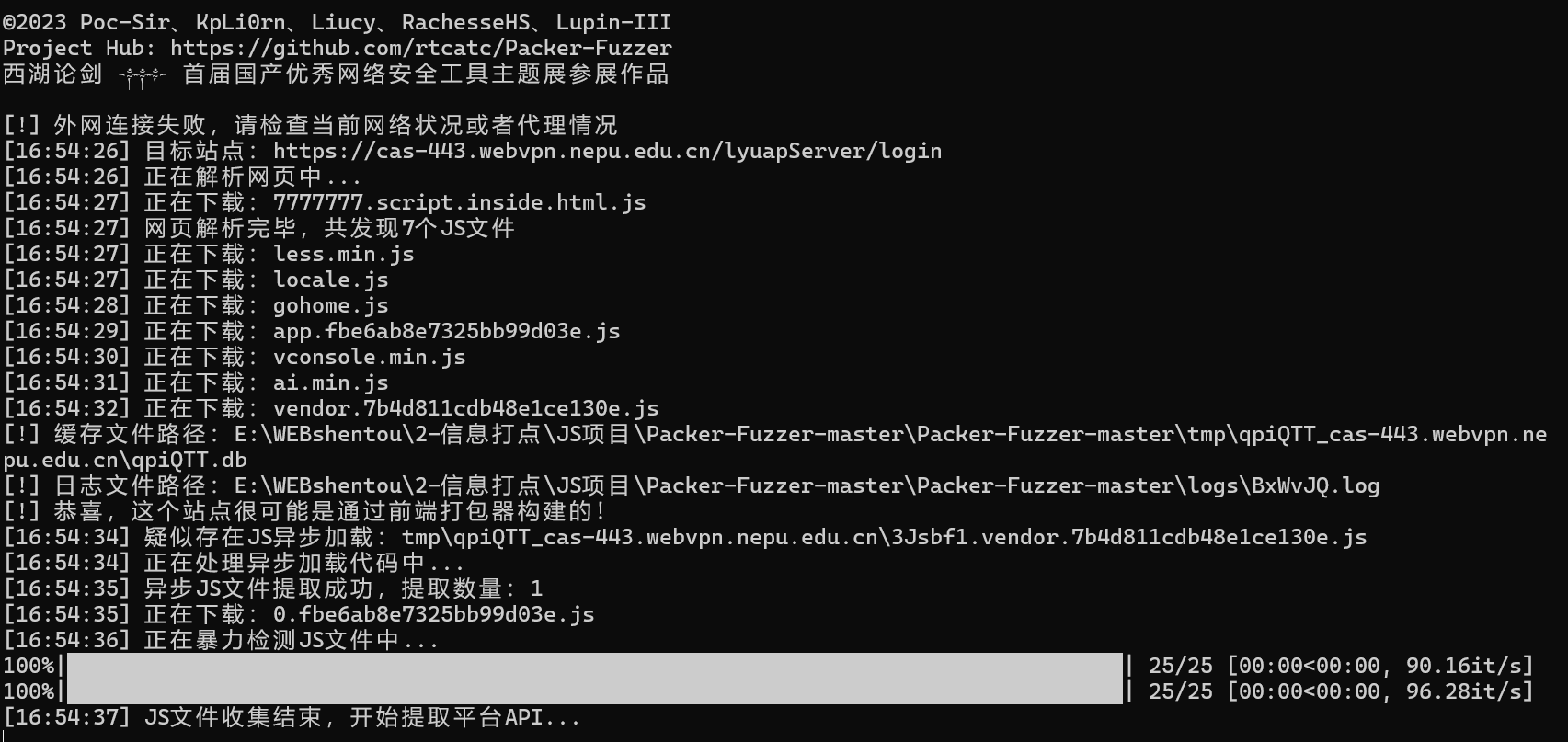
这个是用来识别对方是否为框架搭建的,然后可以检测是否有一些简单的漏洞,然后会生成报告

比如这种的,虽然基本上没什么作用
所以最后为什么要看这些js源码呢,这就涉及到js相关的安全问题了
源码泄露
未授权访问
通过某些没认证却能查看的后台信息,确定更多URL访问从而确定更多接口
敏感key泄露
js代码中配置的一下接口信息(云应用,短信,邮件,数据库等等)
api接口安全
代码中的加密提交,和各种提交数据传递,跟多的URL路径
上面的工具就可以提供给我相应的信息,我们需要的是有价值的信息,首先就是通过源码提取
然后FUZZ工具可以提供未提取的js文件
再可以使用WEBPACK进行简单的漏洞猜测试
web应用认识
一个web应用有很多的开发框架和语言,有些网站在控制台中就可以看到使用的是什么搭建的,比如我的这个博客

一看就知道是apache搭建的哈,但是有些项目浏览器并不能直接查看,比如java相关的,这时候我们应该怎么确定框架呢,这时候我们就要知道网站端口的作用了,默认情况下各个框架都会开启一个默认的端口号,比如http服务会使用80端口,而java应用会使用到比如tomcat会使用8080端口这种
而这个时候我们怎么确定他这web开启了哪些服务,启用了哪些端口号呢,这时候就要使用神奇的端口扫描小工具了
而端口扫描一般用的比较多的就是nmap masscan 和其他的一些网络空间比如鹰图、fofa啥的,都可以扫描一些开启的端口。
首先我们看一下nmap的使用
打开就是这个样子咯
目标就是你要扫的目的地址咯,配置下面有很多种,还有下面的命令,其实是一个东西,这里就不过多一一赘述,问度娘
我们先来开扫一下看看是什么样子的,使用我自己的
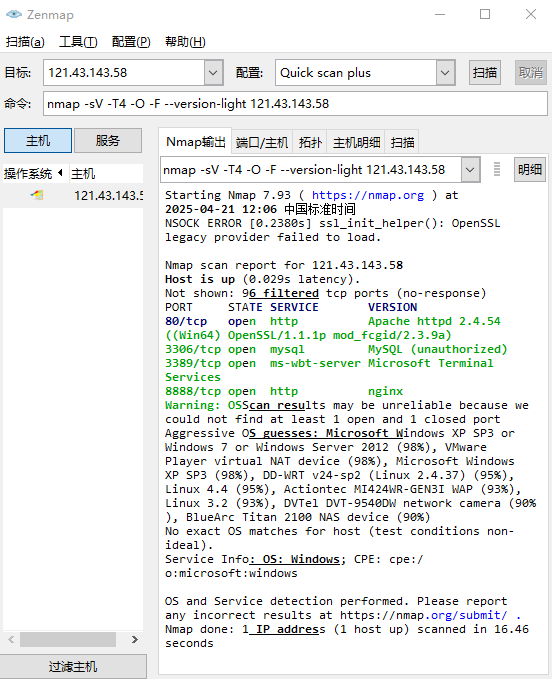
这里也可以看到我的网站是使用什么架构搭建的,apache
下面也可以看到我开启了哪些端口,当然这是简单模式扫的
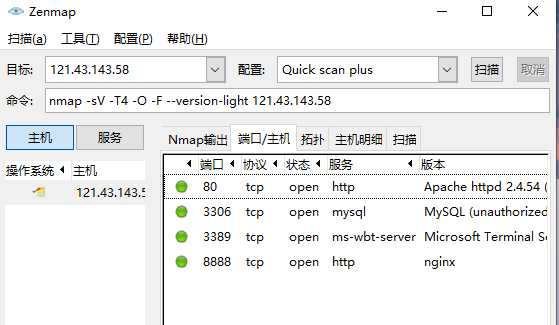
这里可以更清楚的看到开放的端口和服务,
当然我们还可以使用命令行,比如我用kali来扫描一下
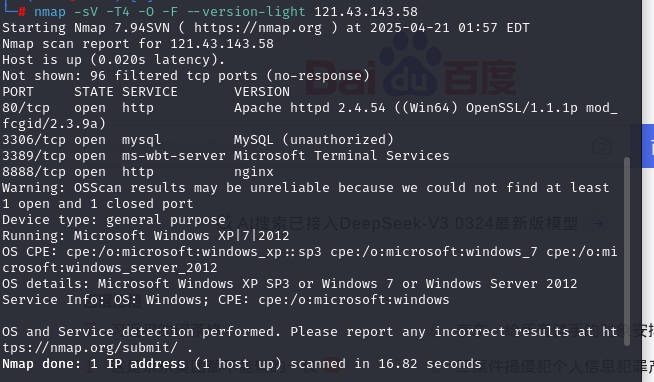
也是可以实现同样的效果的
而我们要知道一个端口的状态
首先是open和close
这个就很简单,开启和关闭状态
还有一个filtered状态
这个是过滤的意思,他可能是开的或者是关的,但是最主要的是因为他被某些防火墙给过滤了,
在他本地有可能是打开的,只是被防火墙阻止了外面的流量通过,所以就会显示这种状态
我们继续看下一个工具的使用
masscan
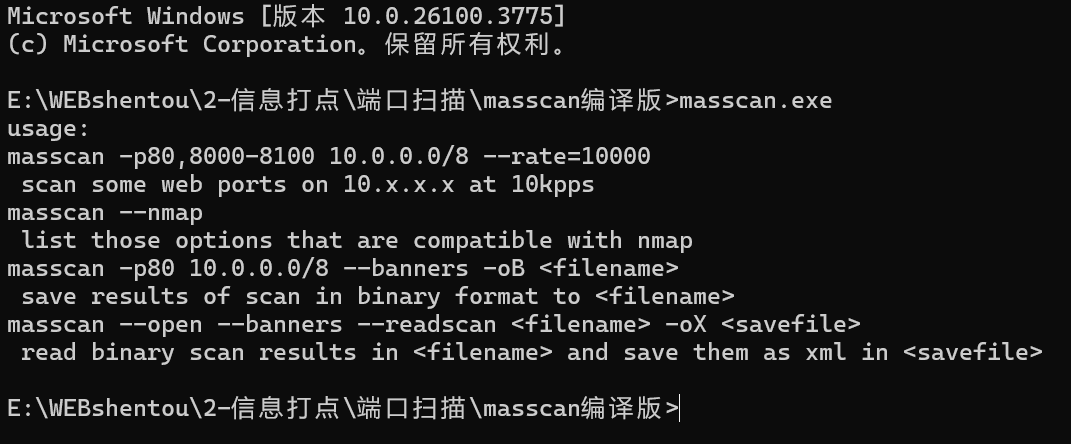
这就是他大概的使用说明,我们来看看效果
masscan.exe -p8080,80,3306,8888 121.43.143.58 masscan.exe -p1-65535 121.43.143.58 //这个就是直接扫描所有端口号了
这个命令就是扫描一些常用端口是否启用,我们上面用nmap扫描过了,所以知道哪些端口是开放的,我们用这个再来看一下

可以看到他也可以探测某些端口是否开启,而我的8080没有开,所以他这里就没有显示
再看看网络空间是否可以,这里使用的是fofa
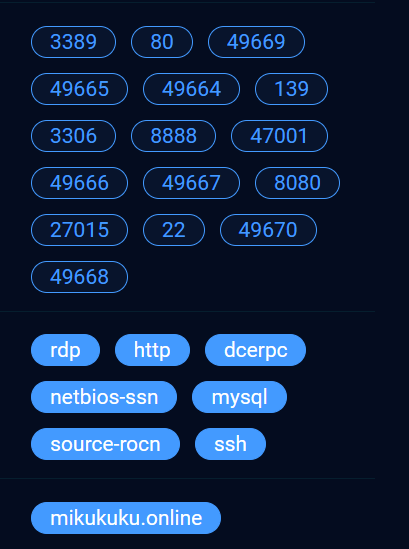
可以看到他直接是把所有开启的端口都显示出来了,还有我的域名
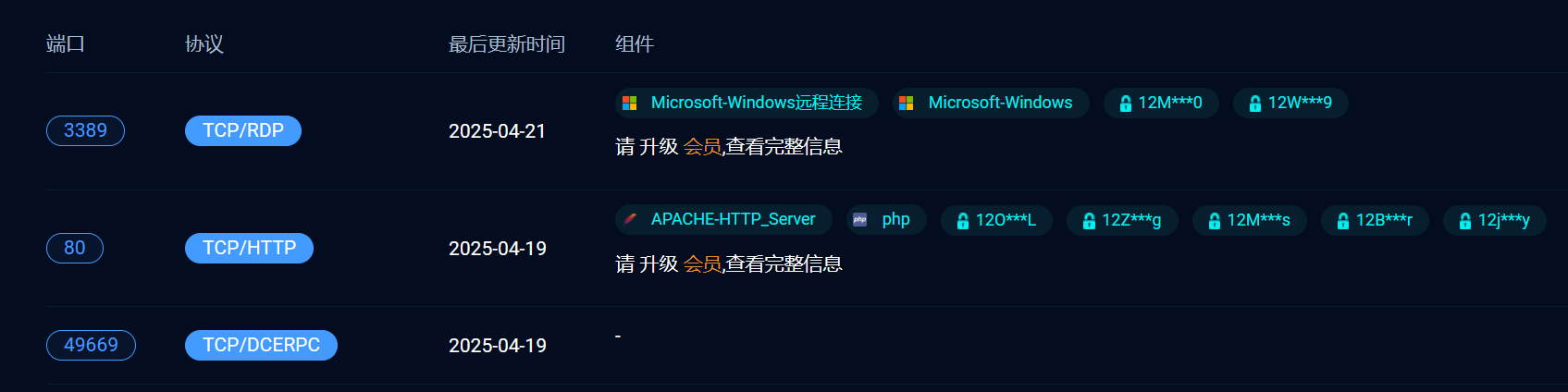
下面还可以看到对应端口号对应的服务,所以网络空间还是很方便的,弊端就是有些需要花米,还有他有些太新的网站没有更新,所以有些他搜不到
最后总结就是端口扫描可以查看目标开放了哪些服务,从而对服务进行精准的渗透测试,但还有种意外情况需要我们考虑
首先是防火墙,有时候你虽然扫描到了对应端口但是对方对此端口进行了防护,从而导致你的某些测试手段无法使用,这个到后面还要学习关于防火墙的绕过,这里就不多说了
还有一个是他的服务器是在内网环境里的,只是把某个端口映射到外网上,虽然你扫描到了某个端口但是其实他只是映射到外网的,测试目标主机的时候发现最终其实他并没有打开(排除防火墙),也会导致渗透失败,而这种情况貌似没有办法解决,寄!!
豪德,既然现在提到了防火墙,就不得不说关于web应用的防护了,也就是我们常说的WAF,网站应用级入侵防御系统,是专门针对web应用防护的系统
前面我们学习了各种的信息打点然后打算一展宏图,结果发现憋佬仔的居然有防火墙,嘻嘻,原地下班!!谁懂这种救赎感~~
所以我们还要学会WAF识别,来看看目标是否启用了waf,然后从入门到放弃。
首先我们来看看网上经常会听到的WAF分类
云WAF:百度安全宝,阿里云盾,长亭雷池,华为云,亚马逊云
硬件WAF:绿盟,安恒,深信服,等等
软件WAF:宝塔,安全狗,D盾等
代码WAF:这种一般就是项目开发的时候直接写在代码里的
所以我们该怎么识别呢
首先就是用你的big眼睛看页面,各种防火墙都有自己相应的拦截页面
举个例子

心肺骤停了属于是
首先我们来一眼顶针
//随便访问一个网站
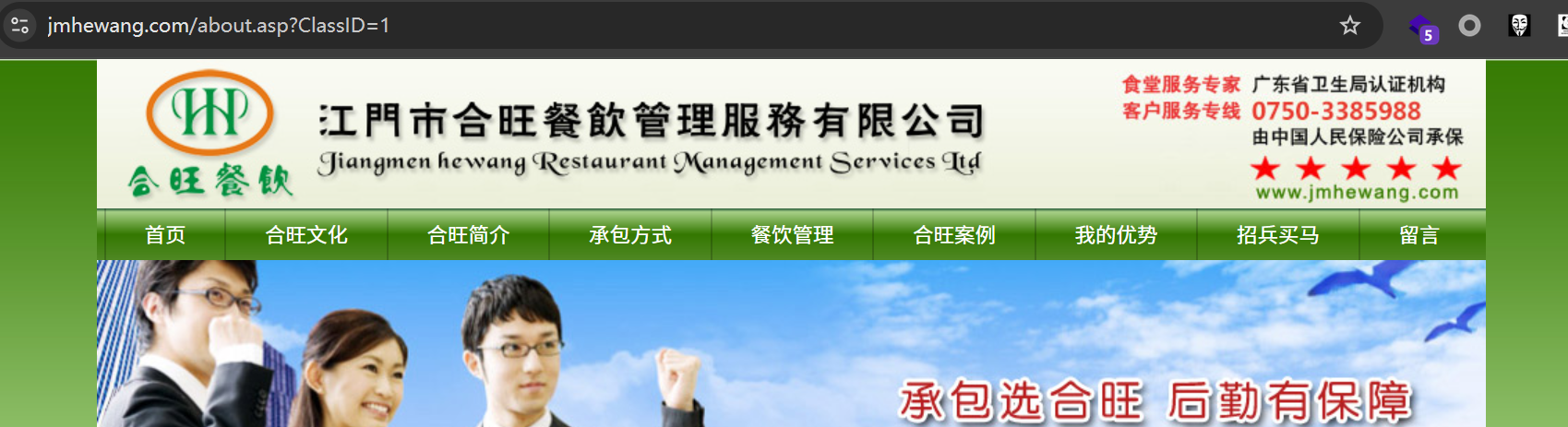
我们在url中随便构造一个语句

可以看到也是成功的被拦截了,一看就知道是安全狗的
那再用小工具试试呢
wafw00f-2.2.0
首先我们来看一下这个工具
首先我们要安装一下哈
python setup.py install //如果安装失败有可能是因为缺少了某个模块,可以试试这个命令 pip install setuptools
然后在工具的对用目录中会生成一个同名的文件夹
我们在这里使用工具
首先检查一下能不能正常打开,再来试试识别一下
python main.py https://jmhewang.com
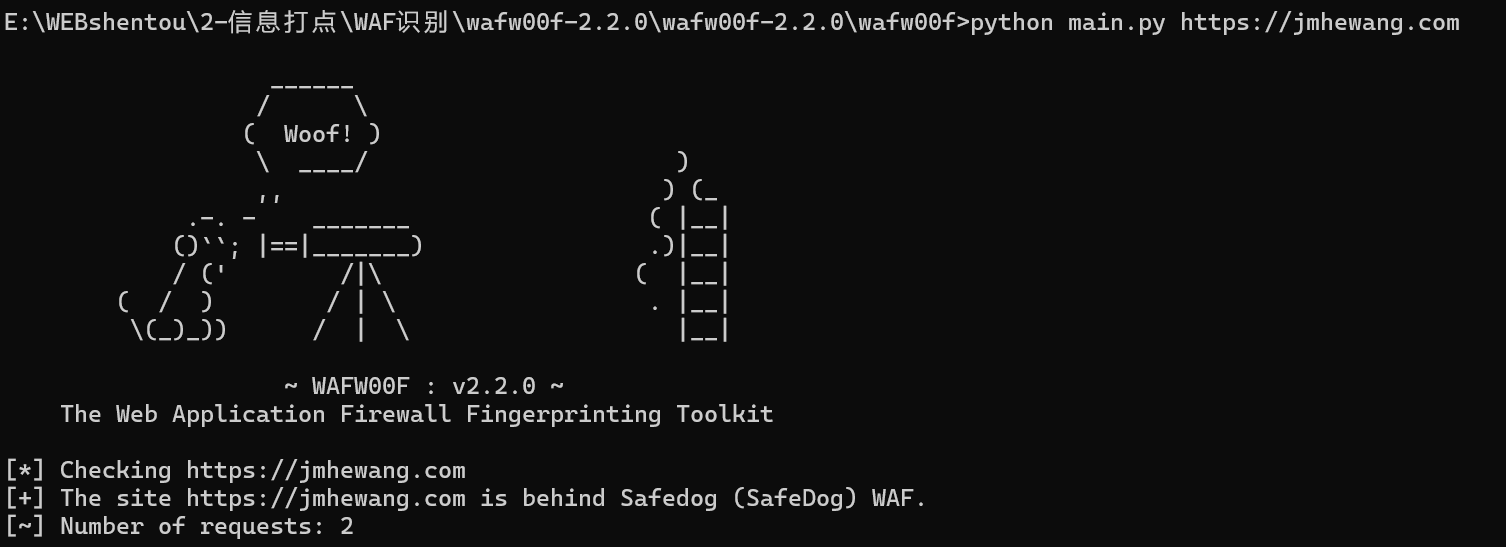
可以看到他也是识别到了哈Safedog WAF也就是安全狗哈
我们再看另一个例子
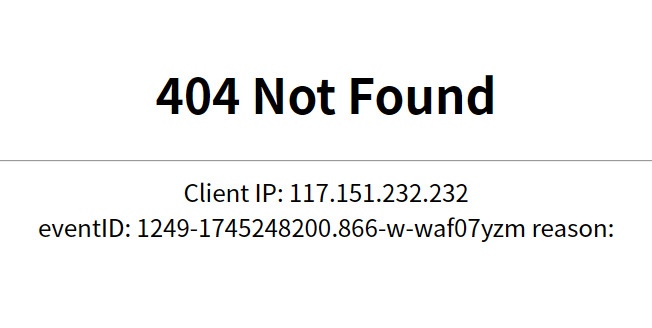
可以看到这个叽里咕噜你也看不懂发生甚么事了,我们再用工具查看一下
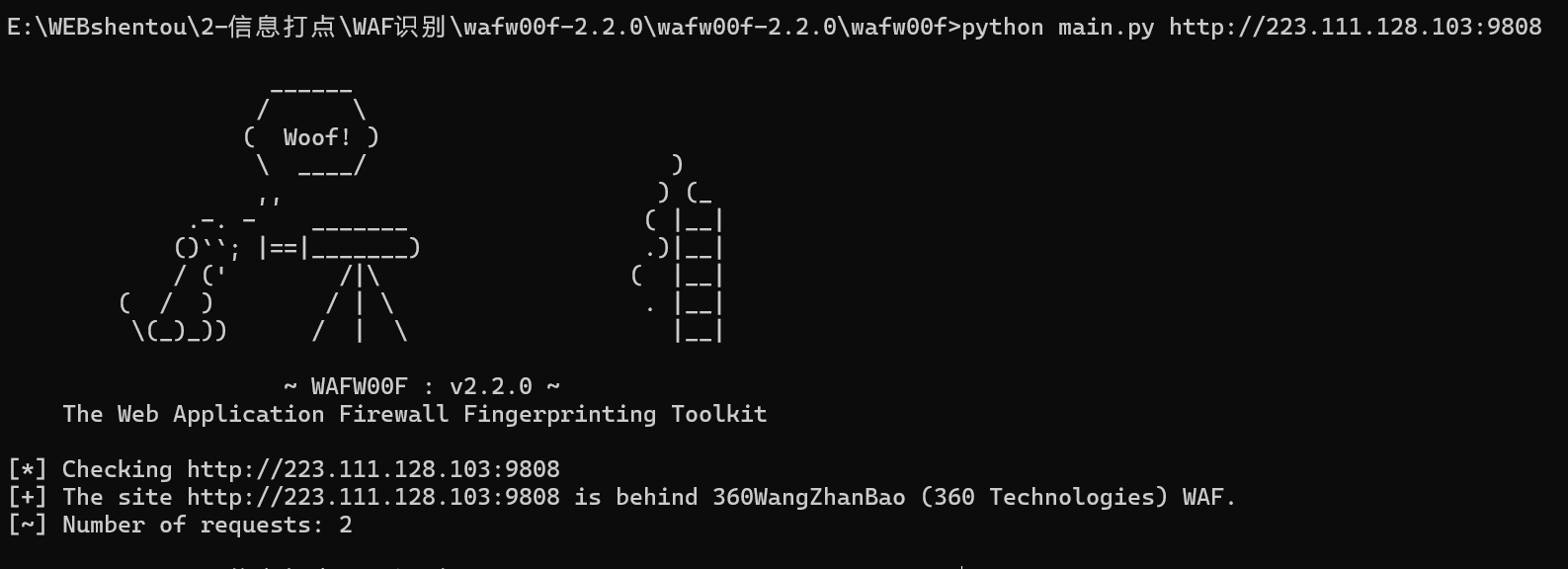
可以看到360的一个WAF
我们再来看看另一个工具
identYwaf
python identYwaf.py https://jmhewang.com
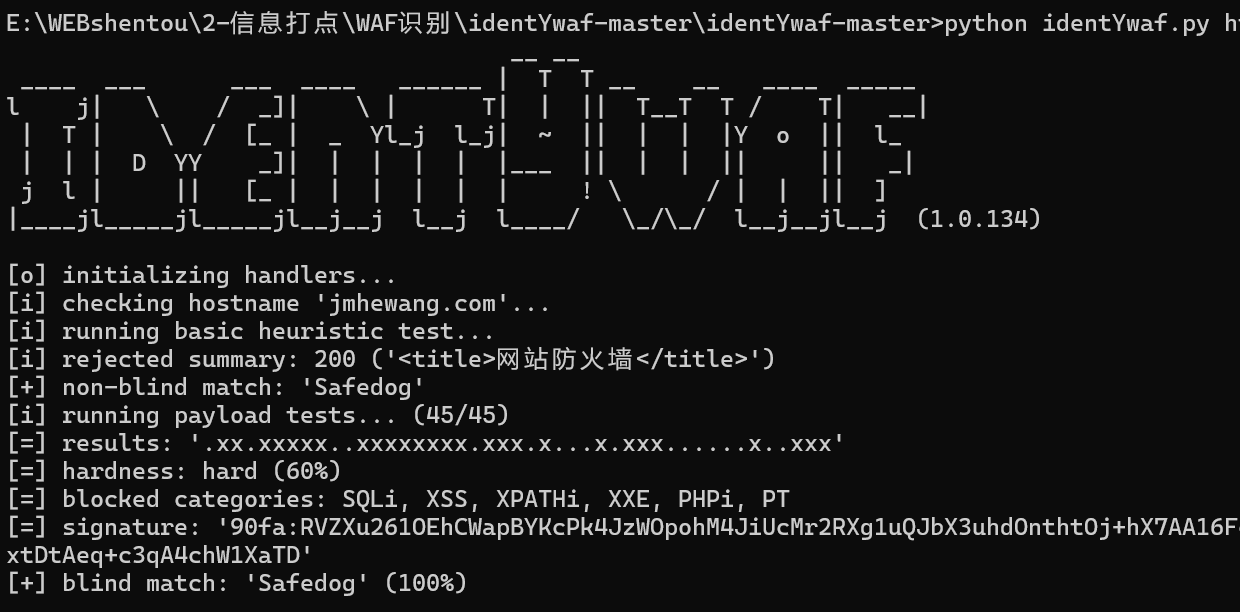
也可以成功识别
WAF讲到这里也就差不多了,没什么好说的,真正在渗透的过程中遇到了WAF基本就可以放弃了,以现在的技术来说,基本很难绕过了,所以没必要花太多精力硬日(大力王难绷表情)
然后还有一个特别的技术
蜜罐
蜜罐是什么呢,它是一种安全危险检测技术,通过引诱攻击者攻击,记录攻击者的攻击日志,通过分析日志来推测攻击者的一图和手段
简而言之就是对着一个假的目标一直日,这谁受得了,所以我们还要学会识别目标是否为蜜罐平台
根据蜜罐与攻击者之间进行的交互的程度可以将蜜罐分为三类:低交互蜜罐、中交互蜜罐、高交互蜜罐,还可以根据蜜罐模拟的目标进行分类,比如:数据库蜜罐、工控蜜罐、物联网蜜罐、WEB蜜罐等等
多的不说,直接上实战
气死我了,用乌邦图部署半天没用,最后还是选择用windows部署
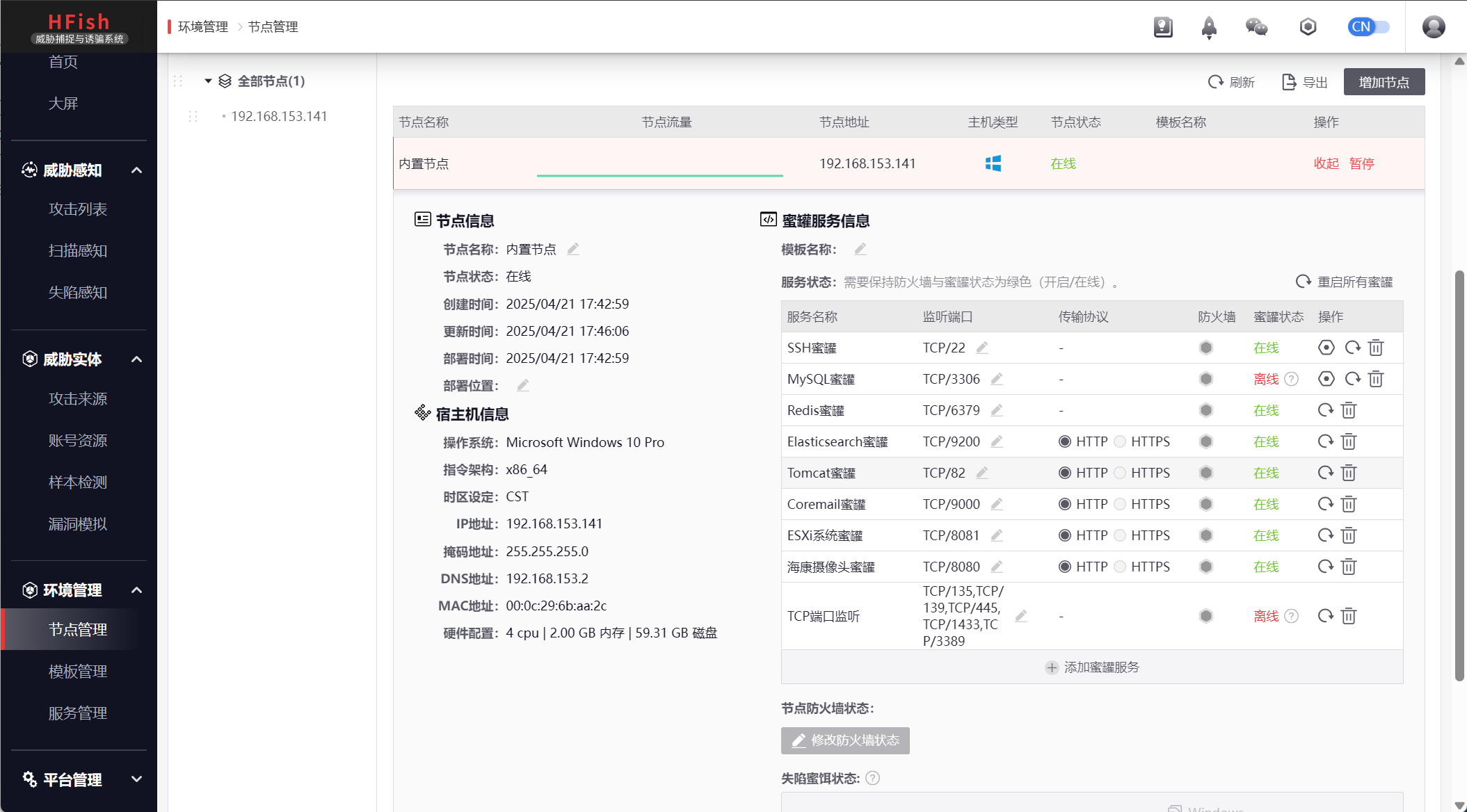
打开就这个样子,我们去访问一下web服务
随便输然后去后台查看一下

可以看到攻击者的ip更详细的在点开就可以看到了
当然这里并不过多的讲解这个平台,只是让大家看一下蜜罐的样子
所以说我们要怎么识别他是不是蜜罐平台呢
首先是一个谷歌插件
Heimdallr
我们访问一下刚刚的网站

可以看到他这里就有提示,这就基本可以确定是一个蜜罐网站,哪有那么容易就有一个直接漏洞个给你看见的,傻不傻。只不过工具还是工具,有时候也不太准,这个工具还不是很好用,只能简单判断
还有一个工具就是360夸克的一个识别工具
quake_rs
这个需要官方的api key 所以需要自己注册账号
首先使用
quake.exe init //后面接上自己的api
初始化他
然后使用
quake.exe honeypot + 目标IP

因为我这个虚拟机上面还部署了别的网站,所以现在显示的是正常站点,如果他能识别出来是蜜罐的话就是另一个样子了
还有最后一个就是本人识别了
一般就这几个规律
端口多有规律性
前面我们部署的时候也看到了,他启用的各种服务,他下面还有更多模版,所以这种一般都很好识别
web访问协议下载
而这个的意思就是由于他是有一个后台的,然后前面攻击者攻击产生的数据最后会被记录到后台中,但是需要一个
协议去传输到后台,类似于jsconp去传输,当你用浏览器访问这个端口的时候,就会采用协议去下载文件
设备指纹分析
具体看这个文章哈
根据不同蜜罐然后访问去分析返回值来判定是否为蜜罐
这样的话蜜罐也差不多完了
CDN绕过
很早以前就提过CDN是什么东西了,这里就不过多赘述,这个东西对安全测试最大的影响就是是否能寻找到真实IP从而正确的进行渗透测试,不然老是对着个CDN提供的IP扫扫扫有啥用嘞,是虚假的。
我们怎么确定他启用了CDN呢
多地ping服务:使用不同地理位置的ping服务检查目标IP地址是否唯一。常用工具包括站长工具、爱站网、360网站测速等。如果返回的IP地址不一致,则可能使用了CDN。
nslookup命令:检测域名解析的IP地址数量。如果解析结果中有多个IP地址,说明使用了CDN。
这时候就要用到神器的小平台了

可以看到各地都解析到同一个IP,这样就可以确定他没有CDN,我们来试试百度,这样一对比就一目了然了
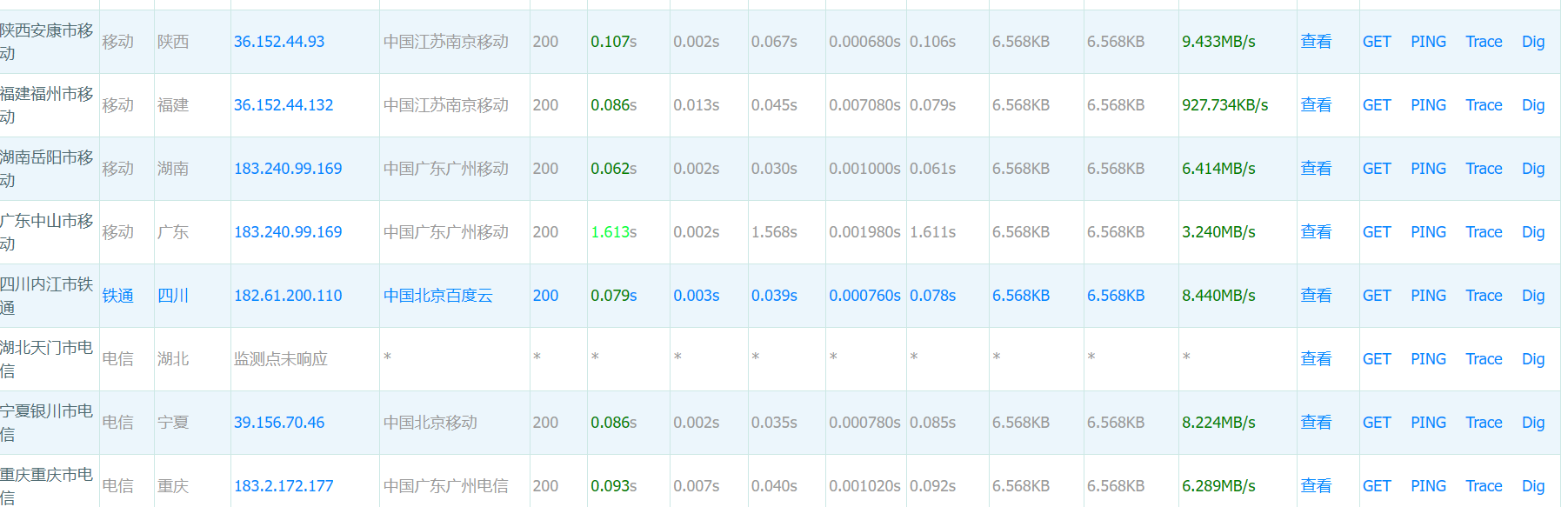
这一看就一目了然了,这么多IP
我么再看另一个平台
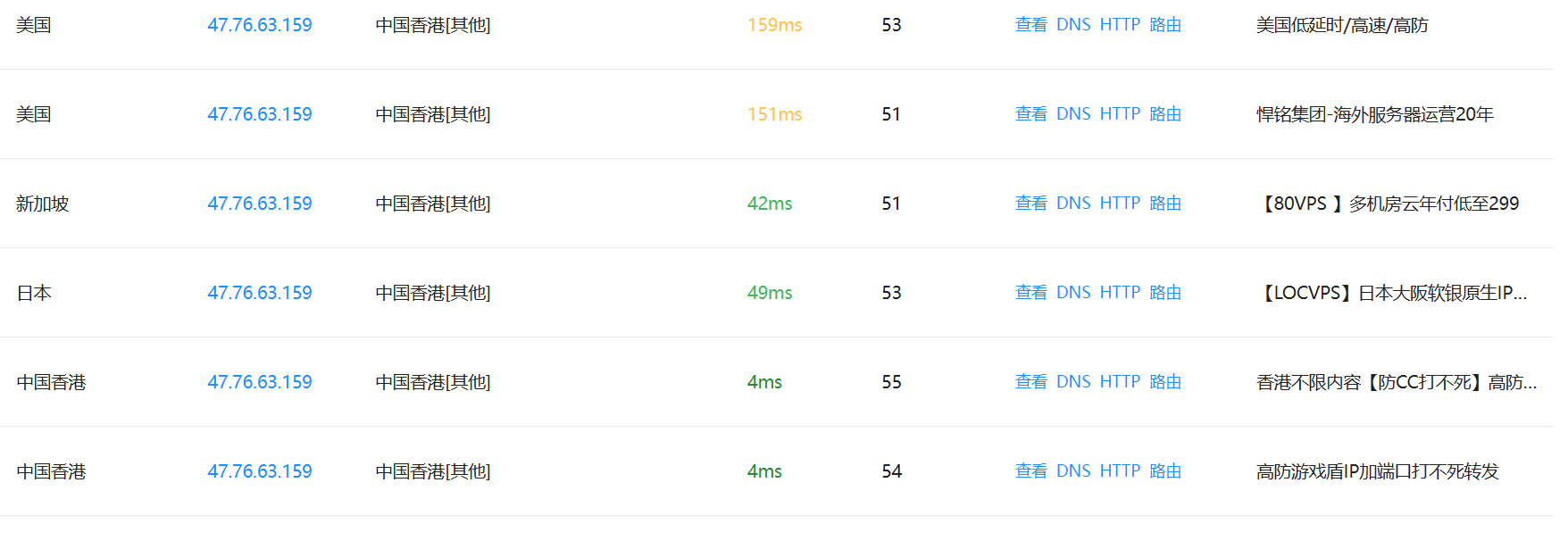
重要的还是国外的测试,一般国外的都是同一个IP的话,那一般就是他真实IP了,当然这只是一般情况
但是其中有个空子可钻,因为CDN加速只针对一个域名,除非说非常有米的话,那就不谈,一个网站比如说我用百度举个例子
我首先ping www.baidu.com
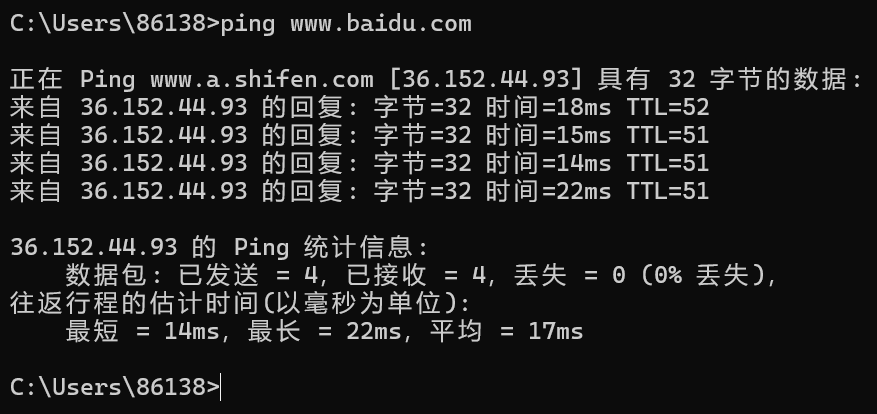
可以看到是这个ip给我提供服务,我要是再试一下他的普通域名baidu.com呢
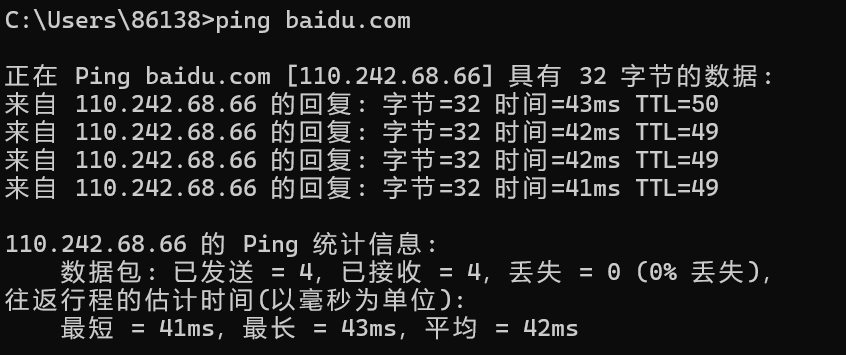
可以看到又不一样了,没准这个就是他的真实ip呢,所以这也是一个思路
还有一个思路就是遗留文件,比如像php搭建项目的时候他一般都会在里面生成一个phpinfo的文件,用来查看php版本的,而这个文件上面可能会暴露出服务器的真实IP地址,我们来看看

可以看到这里会记录服务器ip地址,通过这个也可以有几率查看到服务器的真实IP,甚至还有根目录可以看到,这个比较看运气咯。
邮件系统
让服务器主动向你发出邮件,如果对方向你发送邮件的话,邮件头部的源码中可能会包含此邮件服务器的真实IP地址,因为邮件系统大部分应该都是不能做CDN的,因为他用的是特殊的MX域名解析
所以怎么让他给你发邮件呢
首先就是RSS订阅某个公司的服务了,byd之前不小心订阅到了微软的新闻服务,天天给我发垃圾邮件
还有注册邮箱的时候,会给你发验证邮件
其次就是记性不好的同志了,老忘记密码,找回密码的时候会给你邮箱发验证码,或者是天才,把邮箱密码都忘记了,那很好了。
还有各种业务通知和产品推送
这些都是对方会主动向你发送邮件的场景
我们来看看真实的
首先登场的是墨者靶场
https://www.mozhe.cn/
我们先用平台来看看他是否有CDN,虽然这是废话
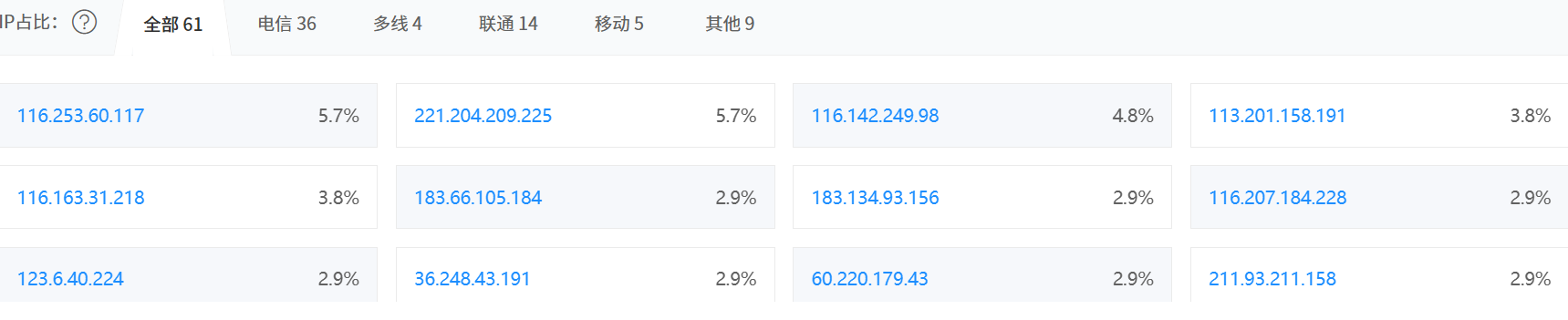
有这么多IP哈,现在我们想寻找他的真实IP,来试试刚刚说的邮件服务,我这个号没绑定邮箱,现在我来假装绑定一下,让他给我发个邮件

好,我现在收到邮件了,我们查看一下邮件原文
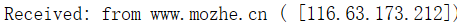
可以发现他这里记录了对方的域名和IP地址,所以一般根据他是否有这两个信息来判断,域名和IP
一般首先观察发信人的邮箱地址是不是他私有的,因为他可以注册一个别的公司的邮箱来给你发送邮件,这种一般就不用看了,肯定是没有的
当然还有你主动出击,但是需要自己的邮件服务器,不能用第三方的,向对方发送一个不存在的邮箱地址,因为不存在会导致发送失败,然后还会收到一个包含该地址的服务器的真实IP
我们拿QQ邮箱举例,向墨者发个邮件
这个对方肯定没有这个地址吧,然后我们发送看看
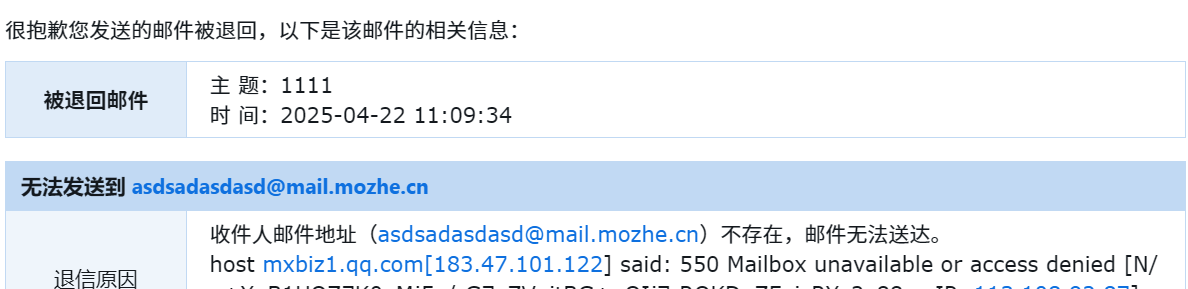
可以看到因为地址不存在然后退回了一个邮件,然后还返回了地址,但是由于中间有QQ挡着,这里只能显示QQ的地址,如果是自己的服务器,那就会显示对方的地址
这里再说一下用来查找CDN接口平台
Get Site IP - Find IP Address and location from any URL
随便查一下那个sp910.com
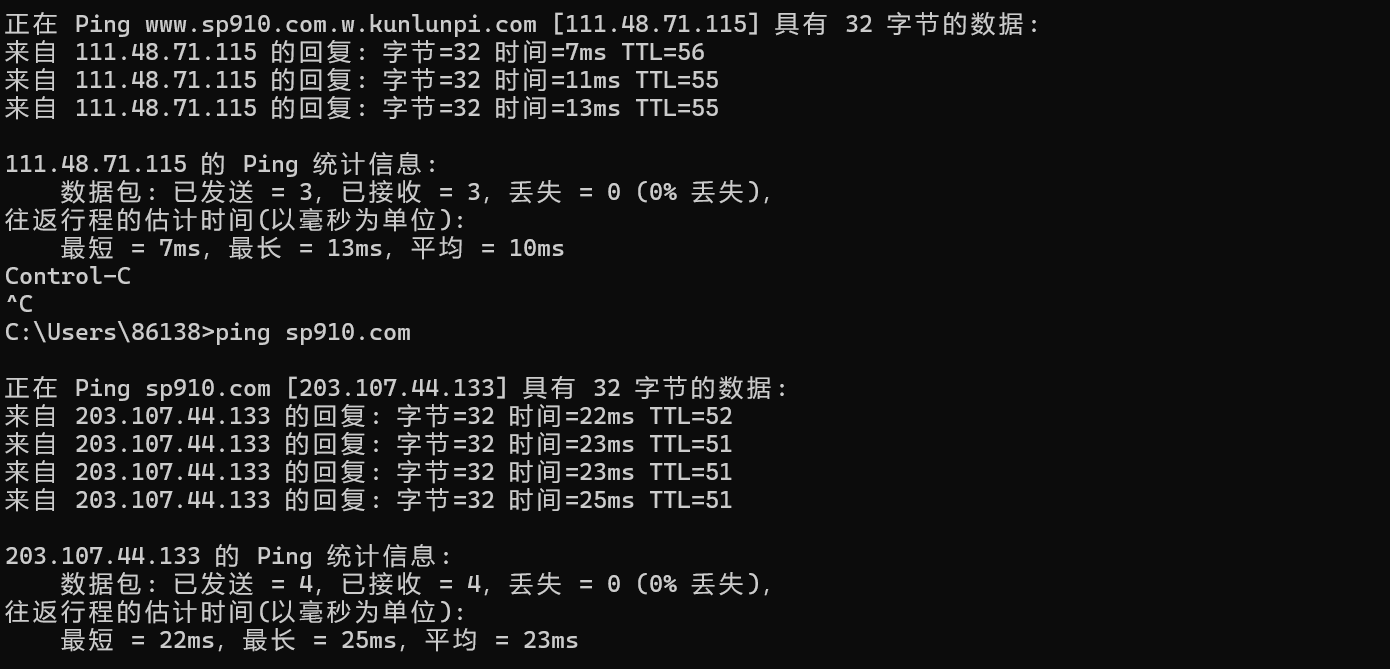
首先我们来ping 一下看他的ip地址

可以看到这个平台也可以查到,然后上面我们ping的时候用前面说过的方法也可以做到,当然肯定也不是百分百,这也只是多条路而已
最后还有个燃尽的办法,全网扫,此方法为最后的底牌,不行那就燃尽了
首先扫描之前要判断一下目标的CDN厂商
平台G了
找到厂商后就要用IP库来扫
用上这神奇的ip库
假如对方是阿里云
用上这个扫描一下常见的IP
然后配置一下扫描的范围
然后就又要用到神器的小脚本了,首先登场的就是fuckcdn
扫描之前先配置一下配置文件

然后配置一下ip文件
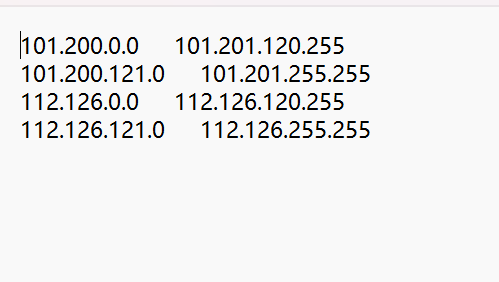
这里就是要扫描的IP,然后上面我们用工具已经扫出来阿里云常用的网段,我们就把他添加进去
当然前面我们已经知道这个网站的真实IP了,我们这里就简单的扫描一下
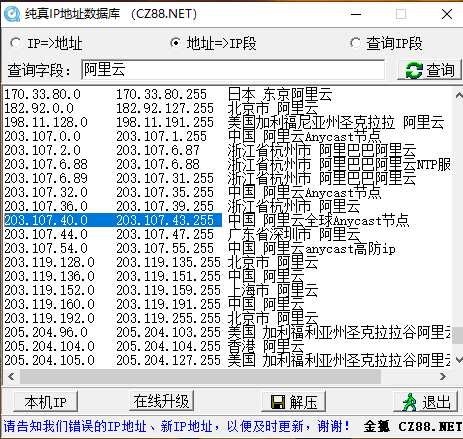
可以看到我标记的这里就是他所在的网段,我们就扫一下这个网段,看能不能扫出来

首先打开工具,这里就是要输入的ip地址是你接受CDN服务器的IP地址,先去ping一下

可以看到是这个地址,那就输入这个ip
不知道为啥老报错,无法解决,反正这工具就这个用法
红色的温
简单的信息打点其实已经没啥了,在最后扩展一点的就是剩余的组件和框架
CMS框架和其他组件识别
前面我们也学习了识别web应用的框架的方法,简单来说就是一套固定的模版来实现需要实现的功能,总不可能每次搭建项目都从头开始敲吧,这个框架就是简单的代码整合,使用框架开发的话只需要学习框架调用即可
比如文件上传功能,框架把这个代码封装起来,你只需要调用一下即可,其实和编程里的函数调用差不多,你写出一个函数体然后封装调用,后面需要用到只需要敲个函数名就可以了,不需要另外敲一遍
所以说这种框架开发的话,主要的安全问题就是框架里封装的代码是否严谨,是否有历史的安全问题,所以像前面说的首先信息搜集的话,当拿到目标之后首先肯定是要判断他的主体框架的,看他用的是什么框架,从而直接可以利用框架的历史漏洞,从而减少测试的精力
比如我这个网站直接是用z-blog部署的,然后就可以看看这个框架的历史漏洞能不能直接利用,可恶,不许攻击我的网站(红温)
另外还有组件的识别,这个就是网站的额外功能了,比如我在后台可以看到的插件,如果需要额外的功能的话直接下载插件使用即可
所以如何识别呢,前面我们已经学习过了在线的指纹识别探针的在线平台的使用,比如潮汐,但是对方的环境要是在内网中呢,这样就无法对目标进行识别了,所以这里再介绍一个工具
Gotoscan

他这个工具的判断方法就是看路径中是否存在这个文件和加密的md5值是否匹配来识别这是什么框架
我们来用用看
打开就是这个样子
gotoscan.exe -host //这里的地址可以是外网也可以是内网,只要能通信即可
用这个语法查一查自己网站

最后就查询到了,这是一个z-blog框架搭建的网站哈

这里可以看到不同的框架都有不同的漏洞,所以说识别框架也可以对安全测试有帮助
web架构
最简单的开发模型(功能代码全部手写)
最容易出现漏洞的模型,由于程序员水平不一,并且由于只是实现见的功能,比如学校老师给你的作业让你写出一个登录或者连接数据库,这种时候一般选择就简单的写出了该功能但是并没有写出加密等等功能,所以这种一般全是漏洞,偷偷去打室友网站,嘻嘻
结合开发框架的开发模型(以框架为核心实现功能)
结合框架后外加组件模型(以框架为核心实现功能,以组件实现扩展功能)
上面这两种就是对封装代码的框架进行安全测试,有些老版本的框架有很多历史漏洞,一般的开源代码网上一搜就一大堆,对于这种web应用最简单的就是找到他的代码源进行代码审计后利用历史漏洞进行渗透
对架构的识别可以对我们安全测试思路有更好的进展,一般大部分的框架都已经成熟了,安全问题基本上很少,虽然也有,那基本上简单的漏洞早就被大肘子一个脚本就扫完了,深入的还是需要手测,看代码是否规范
python开发框架
一般如果用python开发的web应用,一般会使用django&flask这两个框架
Django
插件识别
Set-Cookie:expires=
比如我们随便找个网站进行识别
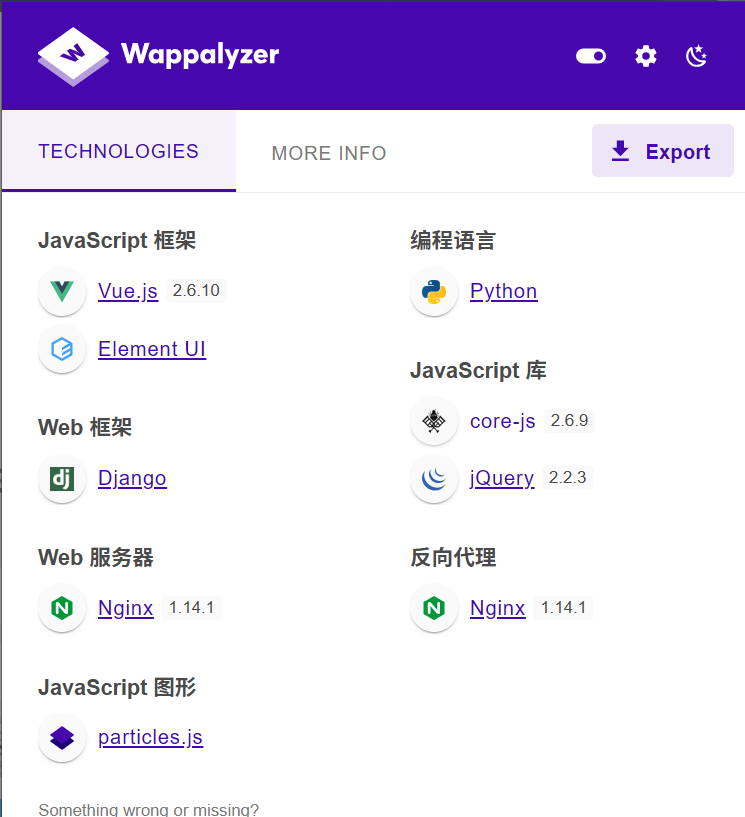
可以看到这个插件可以识别到这个web框架,使用的是python语言写的

通过web头也可以识别出来 一般这个框架的都会带有一个csrfroken这个头
后面的就不放图了,后面都一样,简单的识别
Flask
1.插件识别
2.Set-Cookie:expires=
php开发框架
Thinphp
识别插件
x-powered-by:thinphp
CMS识别到源码体系TP开发
Larevel
识别插件
set-cookie中特征的格式
vli
识别插件
set-cookie中特征的格式
java开发框架
具体可以看这个介绍
52类110个主流Java组件和框架介绍_基于java的组件有哪些-CSDN博客
Fastjson/Jackson
提交JSON数据包中修改测试
-Fastjson组件回吧01解析成1
-Jakson组件在解析01时会抛出异常
Shiro
用于执行认证、授权、加密和会话管理的Java安全框架。
Apache Shiro默认使用了CookieRememberMeManager
其处理cookie的流程是:得到rememberMe的cookie值 > Base64解码–>AES解密–>反序列化。
然而AES的密钥是硬编码的,就导致了攻击者可以构造恶意数据造成反序列化的RCE漏洞。
请求包的cookie中存在rememberMe字段
返回包中存在set-cookie :remeberME=deleteME
请求包中存在remeberME时,响应包中存在rememberME=deleteME
有时候服务器不会主动返回rememberME=deleteME,直接发包即可把cookie内容改为rememberME = 1,若响应包中有rememberME=deleteME,则基本可以确定网站apache shiro搭建的
http://39.98.146.94/eclp/a/login
首先我们看到用插件是识别不出来的,此时我们再看一下返回的cookie
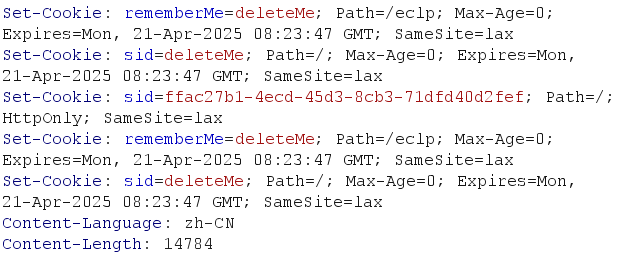
可以看到这种返回的cookie值,那百分百就是shiro框架搭建的了,这个组件适用于安全的组件,用于用户登录,验证用户身份
Struts2
一般使用strusts2框架后缀带do或action,可以尝试进行利用

就像这种网站,他一眼就是用这个框架搭建的
Springboot
通过web应用程序网页标签的小绿叶图标
通过springboot框架默认报错页面
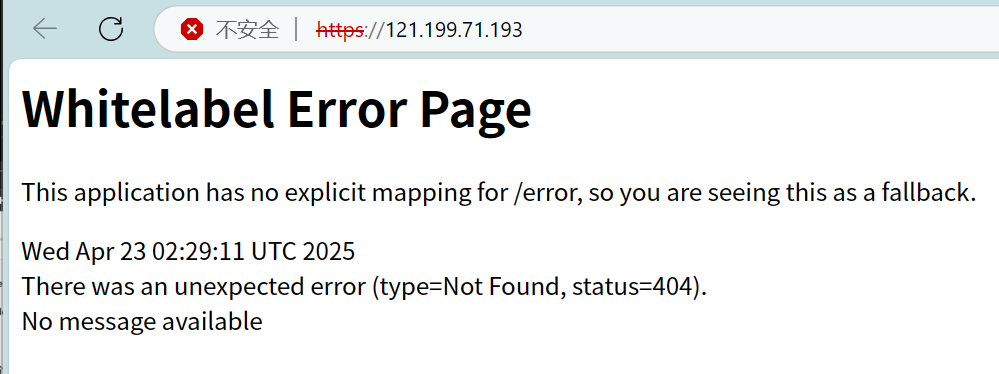
这种就是他框架的默认报错页面,这样就可以识别是否为这个框架
Solr识别
一般开放8983端口,访问页面也可以探针到
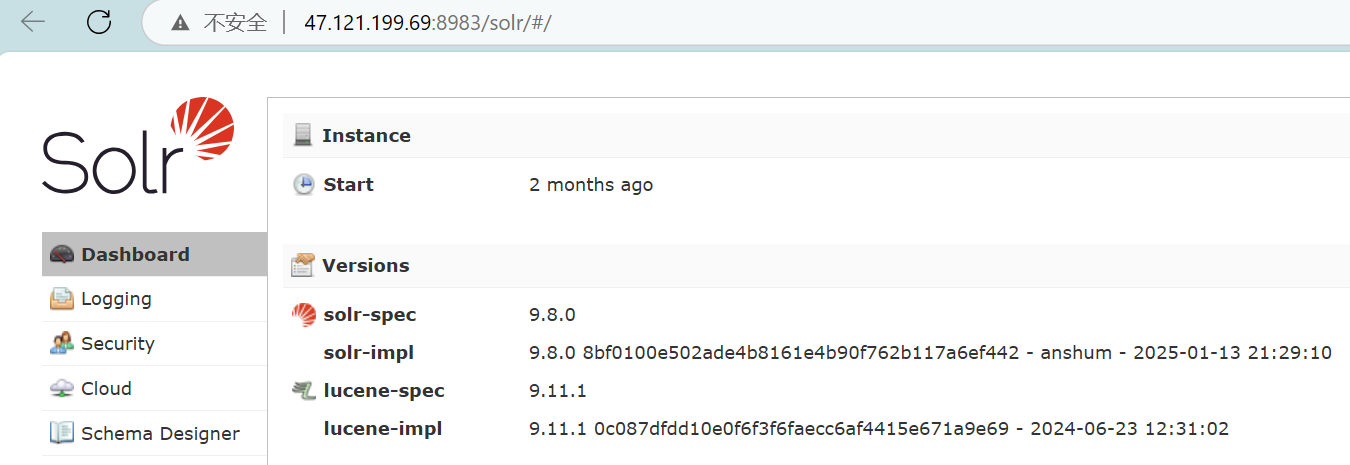
这已经非常明显了小眼睛一下就瞪大了
这个框架是干嘛的呢,他是基于一款全文搜索的搜索服务器,支持多种搜索
说了这么多的识别框架,最主要的就是想知道对应框架的漏洞有哪些,可以直接搜索历史漏洞进行测试
我们来随便找一个漏洞进行测试一下,就拿前面的shiro框架来复现一下,这里使用的是docker环境拉取的镜像
这个我会专门出一个文章去讲的,这里直接看这个漏洞就行
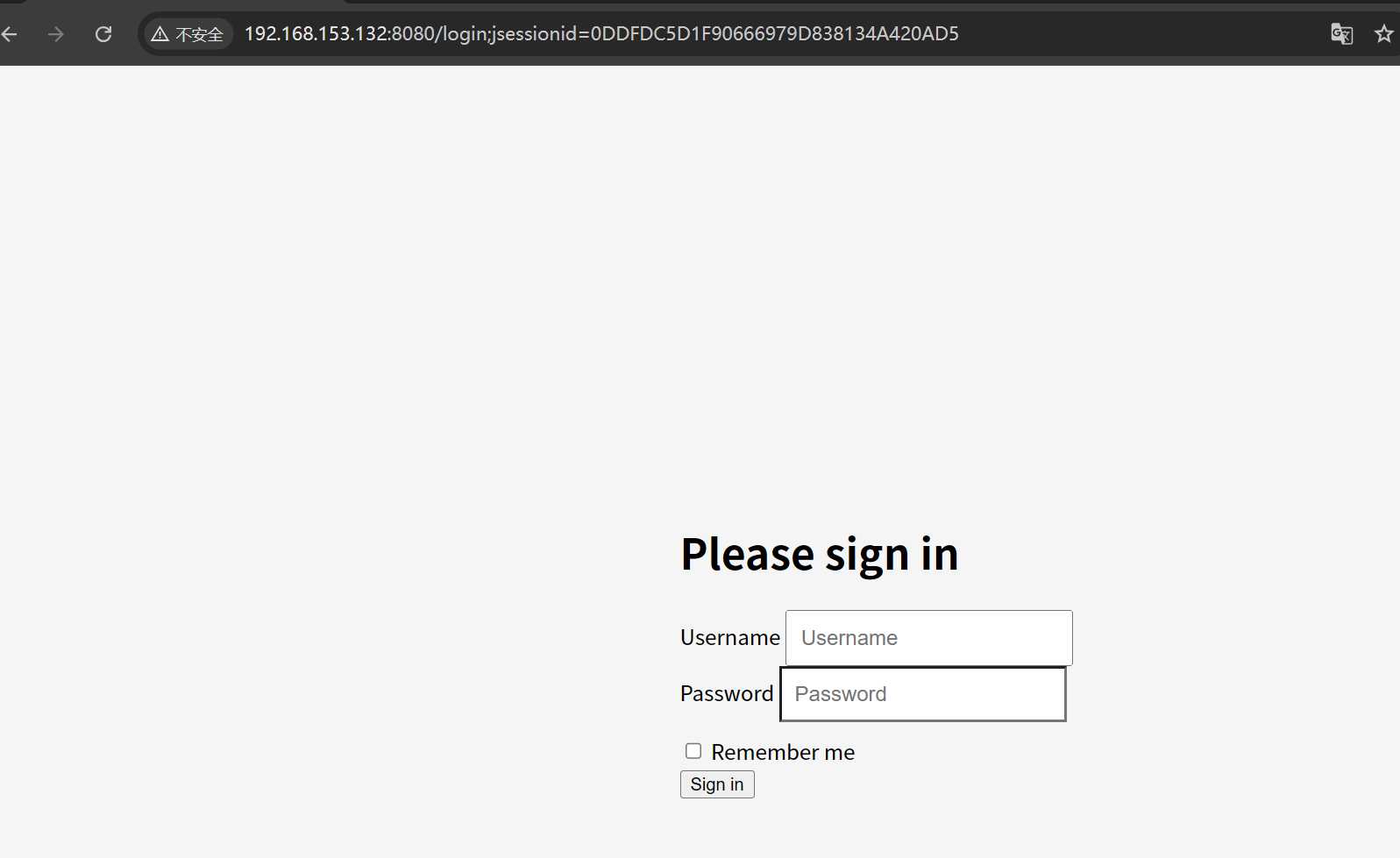
打开就长这个样子
我们叽里咕噜随便登录一下,然后抓到他的登录的包

可以看到上面讲过的shiro框架的特有cookie值,所以可以确定他确实使用的是sihro框架,我们可以利用一下shiro的小工具
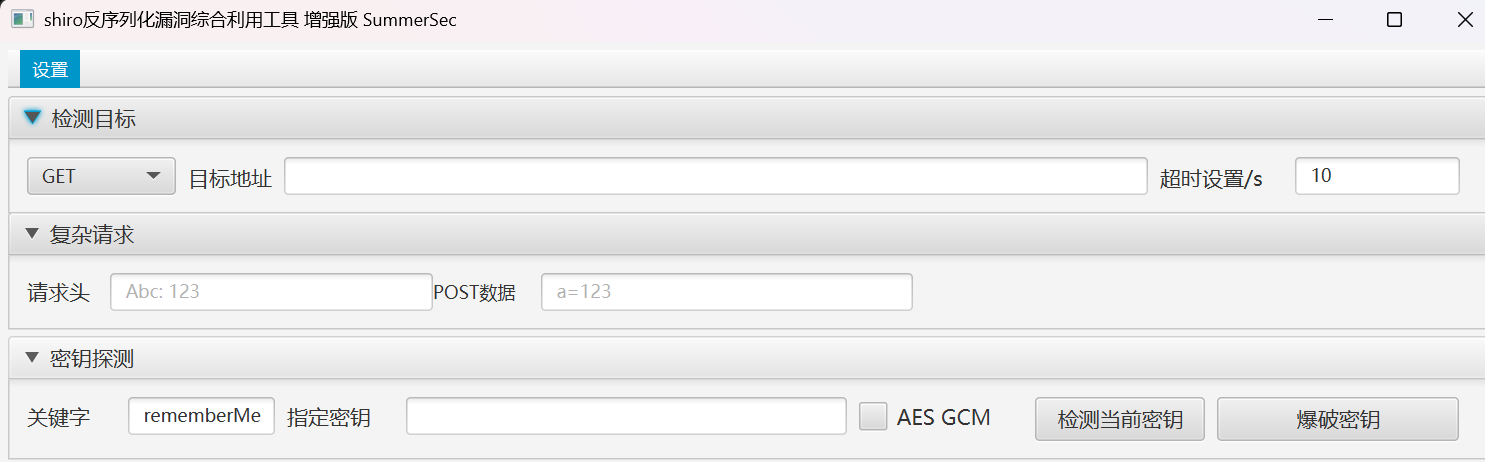
对刚刚那个地址检测一下密匙

可以看到他已经识别到了框架,然后我们爆破一下密匙
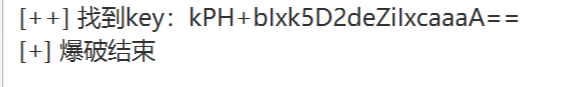
然后检测和利用回显

可以发现已经有可以注入漏洞的地方了,直接去命令执行
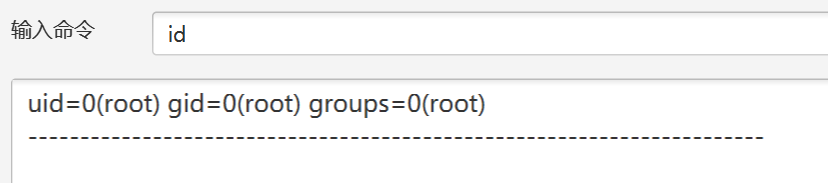
可以发现已经有回显了,我们直接是查看文件夹
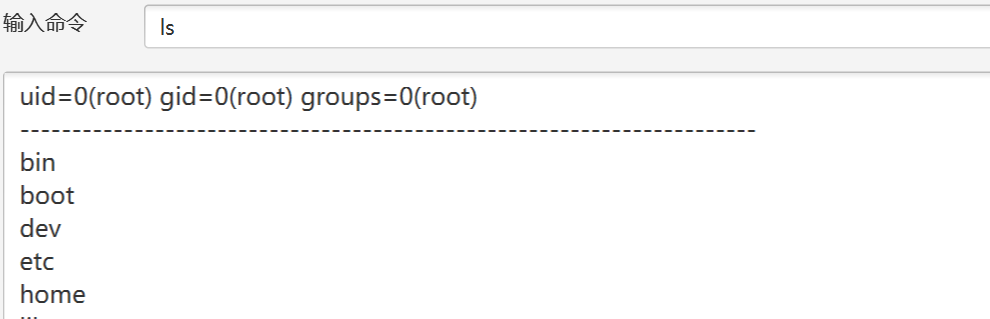
可以看到直接是可以看到敏感信息了,然后我们还可以植入后门

这里使用哥斯拉注入成功后,打开哥斯拉连接
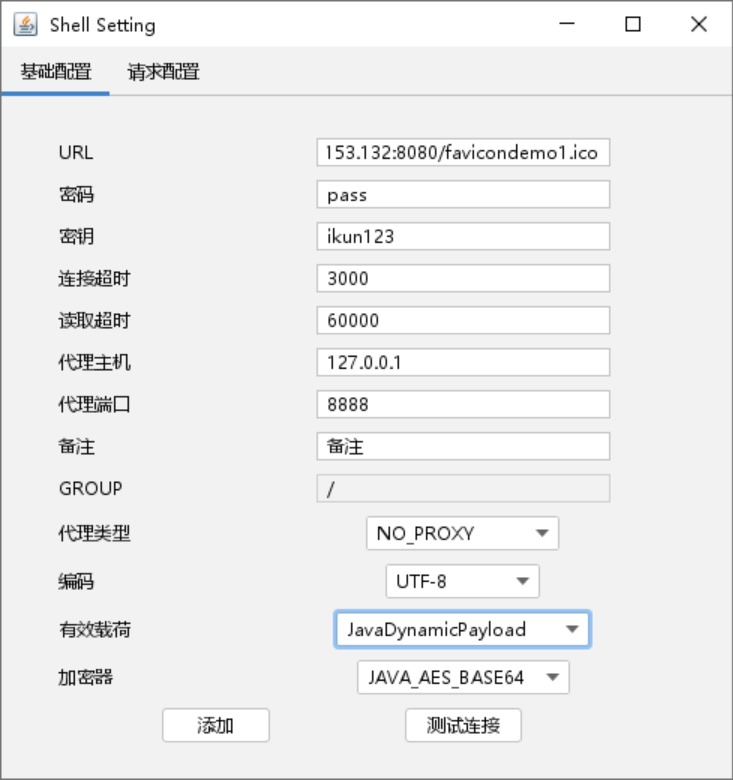
地址密码和key上面都给了,然后下面要选择java
然后测试一下连接
这样就是成功了,我们进去看看
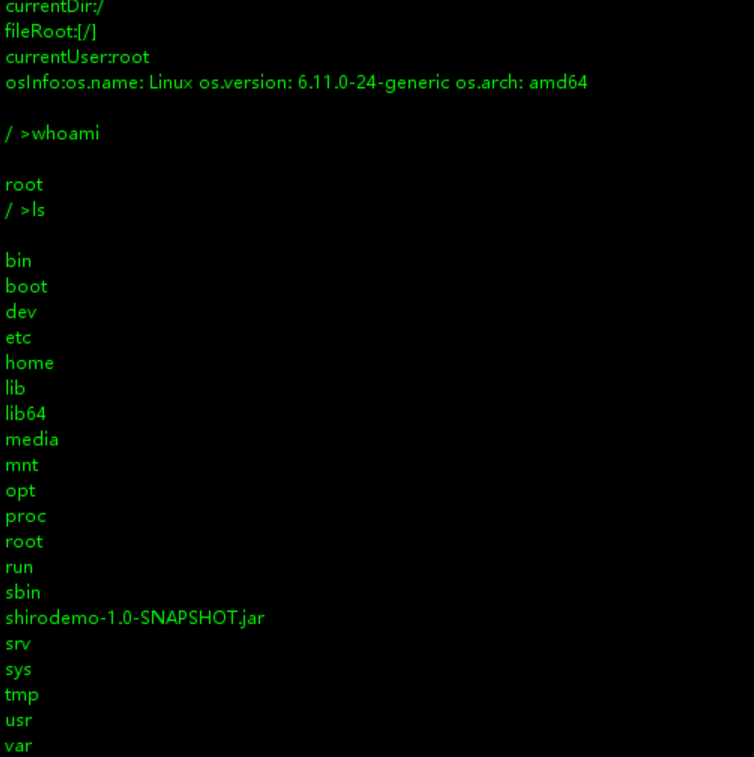
可以看到成功进来了,并且还可以查看文件,非常滴危险。
总结来说,对CMS进行识别,可以更快的进行精准的对漏洞进行利用
前端和后端都基本都是要进行代码审计,所以对语言基础是一种考验,主要看他的逻辑
然后组件和框架大部分常用的框架和组件都有历史漏洞,在CMS指纹识别后查看到框架就可以去搜一搜看有没有历史漏洞,然后小工具直接是利用,但是有些没有漏洞的那就还是得代码审计了,然后挖个0day!!芜湖~~
最后对web应用总结一下就是
首先拿到目标以后第一件事不是对着库库日
思路就是首先是信息搜集,判断一下目标资产的CMS指纹信息,框架,组件,开启的端口号来判断使用了哪些服务之类的,还有最主要的是识别对方的真实主机,对方是否使用了CDN这种服务,还有蜜罐的识别,别人故意漏个洞你就库库日,最后发现日的是空气,那很有生活了
然后还要判断对方是否使用了WAF等防火墙,如果有那可以基本选择润了,人家都有保护了一直日也没用撒
然后通过手动或者工具搜集到对方的各种源码和文件
最后通过框架历史漏洞或者代码审计来找出对应漏洞进行利用,最后获得目标敏感信息,这样一个渗透测试就差不多了,耶~~~
这样关于web信息打点就告一段落了,这个笔记主要还是对web应用打点的一个思路。
暂未完结~






